library(tidyverse) Lab 06 - Better Viz!
Le but de ce laboratoire est de pratiquer l’amélioration de visualisations.
Pour commencer
Nous allons utiliser GitHub Classroom pour que vous puissiez rendre vos réponses. Sur le portail de cours, vous trouverez un lien vers un assignment.
- Cliquez sur le lien
- Connectez vous avec votre compte Github si ce n’est pas fait
- Acceptez l’assignment
- Liez votre compte avec votre nom d’étudiant
Vous devriez maintenant voir un repository appelé Lab06-[votre-username] où devrait être votre nom d’utilisateur GitHub.
Sur la page du repository:
- Cliquez sur le bouton vert:

- Copiez le lien terminant en
.git- Quelque chose ressemblant à
https://github.com/PRO1036/lab06-[votre-username].git
- Quelque chose ressemblant à
Dans RStudio:
- Fichier > Nouveau Projet
- Version Control > Git
- Dans Repository URL : indiquez l’adresse copiée à l’étape précédente
- Choisissez un nom pour le dossier qui sera créé, par exemple “Lab02”
- Choisissez où vous voulez créer le projet dans votre ordinateur.
Cela va copier les fichiers présents sur GitHub, et les copier dans le dossier spécifié. Dans le YAML, le output est réglé sur "github_document". Cela permet d’obtenir un format adapté à GitHub. Notamment, votre fichier final sera un fichier Markdown (.md).
Packages
Nous utiliserons le package tidyverse pour une grande partie de la manipulation des données. Vous pouvez le charger en exécutant ce qui suit dans votre Console :
Données
Les données que nous utiliserons pour les différents exercices sont fournies dans le dossier data/.
Exercices
Le Brexit : Bonne ou Mauvaise idée ?
In September 2019, YouGov survey asked 1,639 GB adults the following question:
En septembre 2019, YouGov a interrogé 1 639 adultes britanniques avec la question suivante:
In hindsight, do you think Britain was right/wrong to vote to leave EU?
- Right to leave
- Wrong to leave
- Don’t know
C’est-à-dire:
Avec le recul, pensez-vous que la Grande-Bretagne a eu raison/tort de voter pour quitter l’UE ?
- A eu raison de partir
- A eu tort de partir
- Ne sais pas
Les données de l’enquête se trouvent dans data/brexit.csv.
brexit <- read_csv("data/brexit.csv")Comme d’habitude, commencez par examiner les données.
Ensuite nous allons créer un premier graphe pour représenter les résultats de cette enquête.
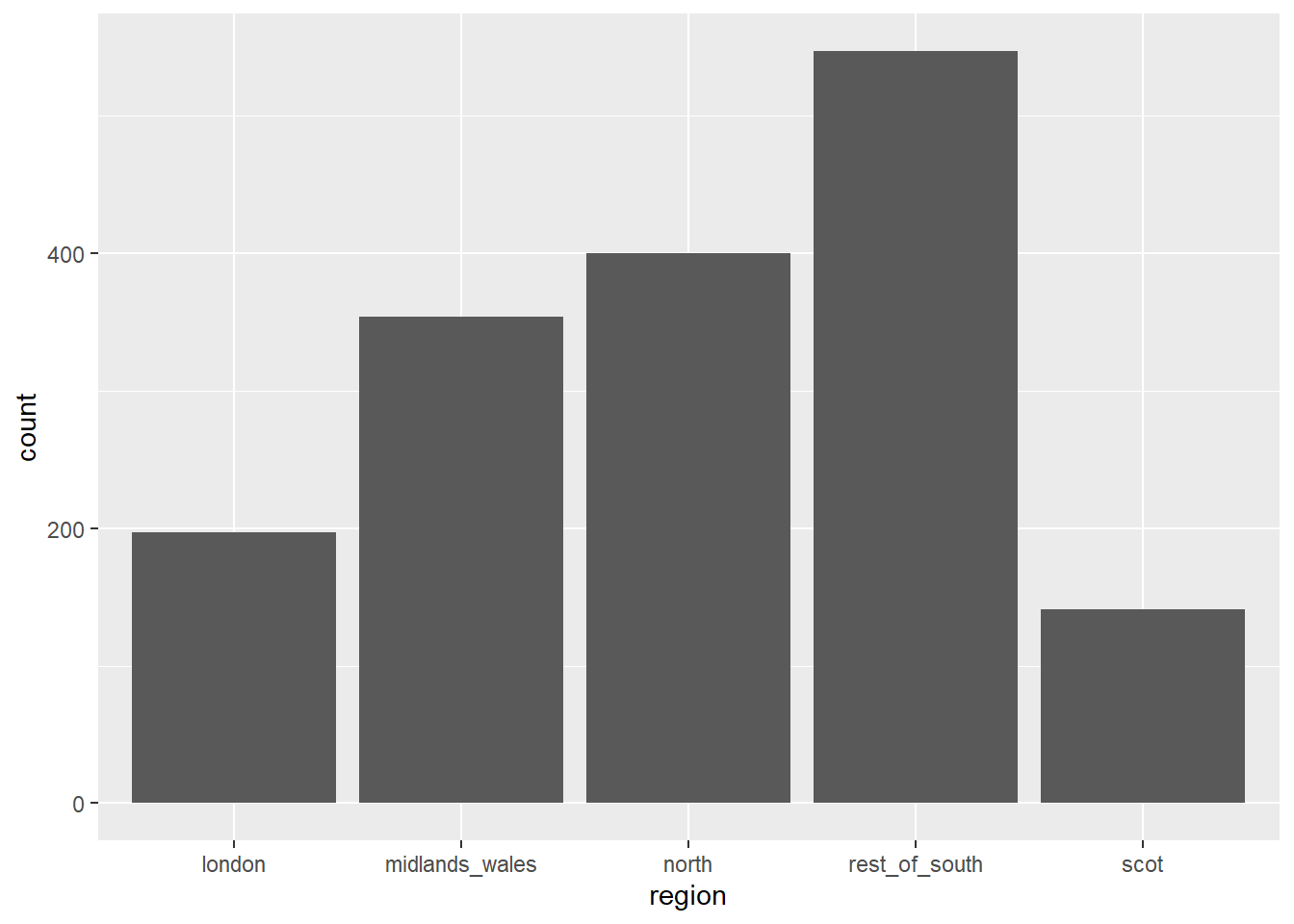
Exercise 1
Pour améliorer cette visualisation nous allons commencer par changer l’ordre des catégories. Ici, elles sont ordonnées alphabétiquement.
Utilisez la fonction appropriée pour réordonner les catégories de la variable region dans l’ordre suivant : london, rest_of_south, midlands_wales, north, scot. Assurez-vous d’avoir des étiquettes lisibles pour les axes et les catégories.
Vous devez obtenir quelque chose comme ceci:
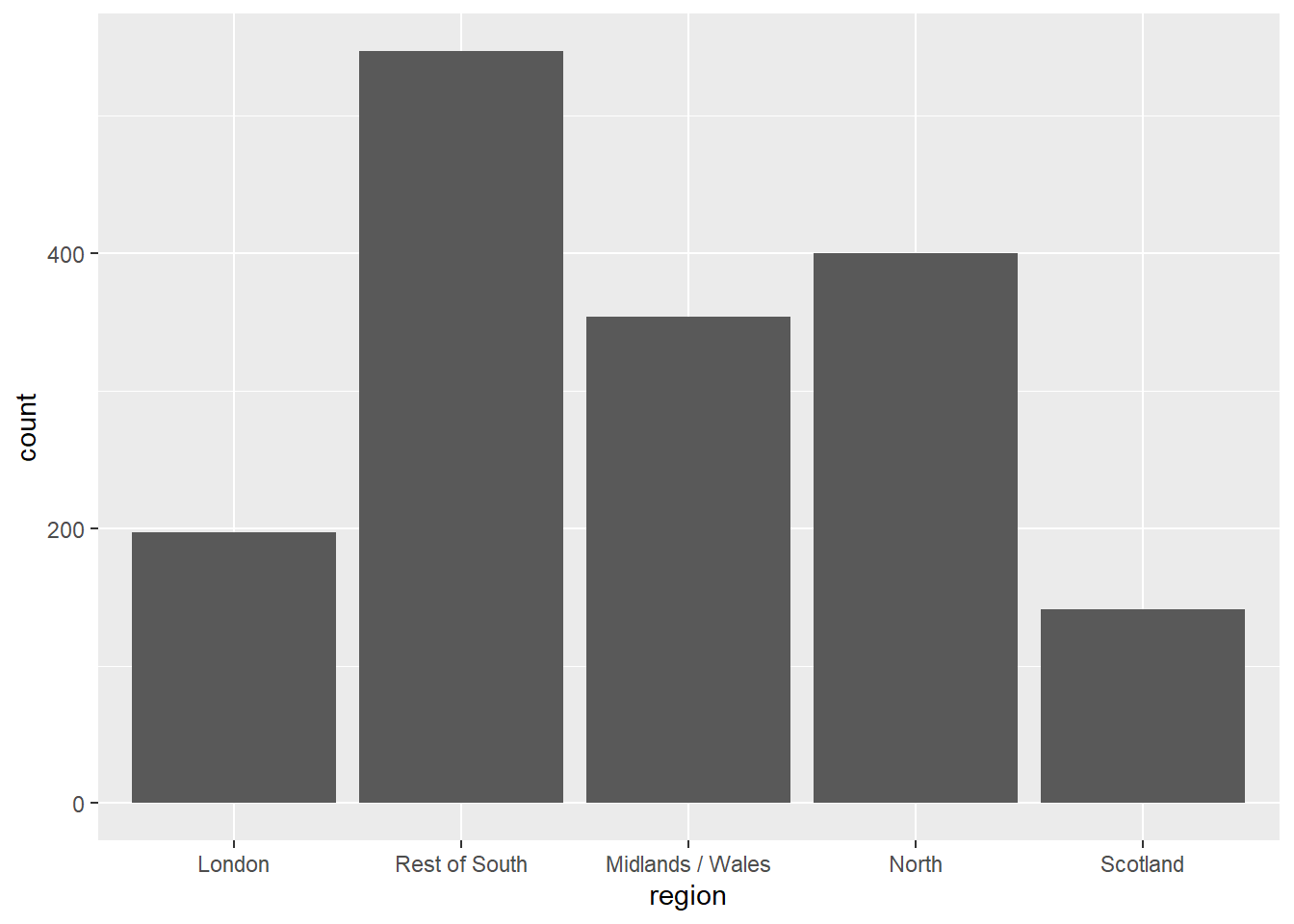
Exercise 2
La lecture n’est pas évidente. Lorsque les catégories ont des noms longs, il est préférable de faire pivoter le graphique pour que les étiquettes soient horizontales.
Reproduisez le graphique ci-dessus, mais avec les barres horizontales. Assurez vous que la première catégorie soit en haut et que les étiquettes soient adaptées.
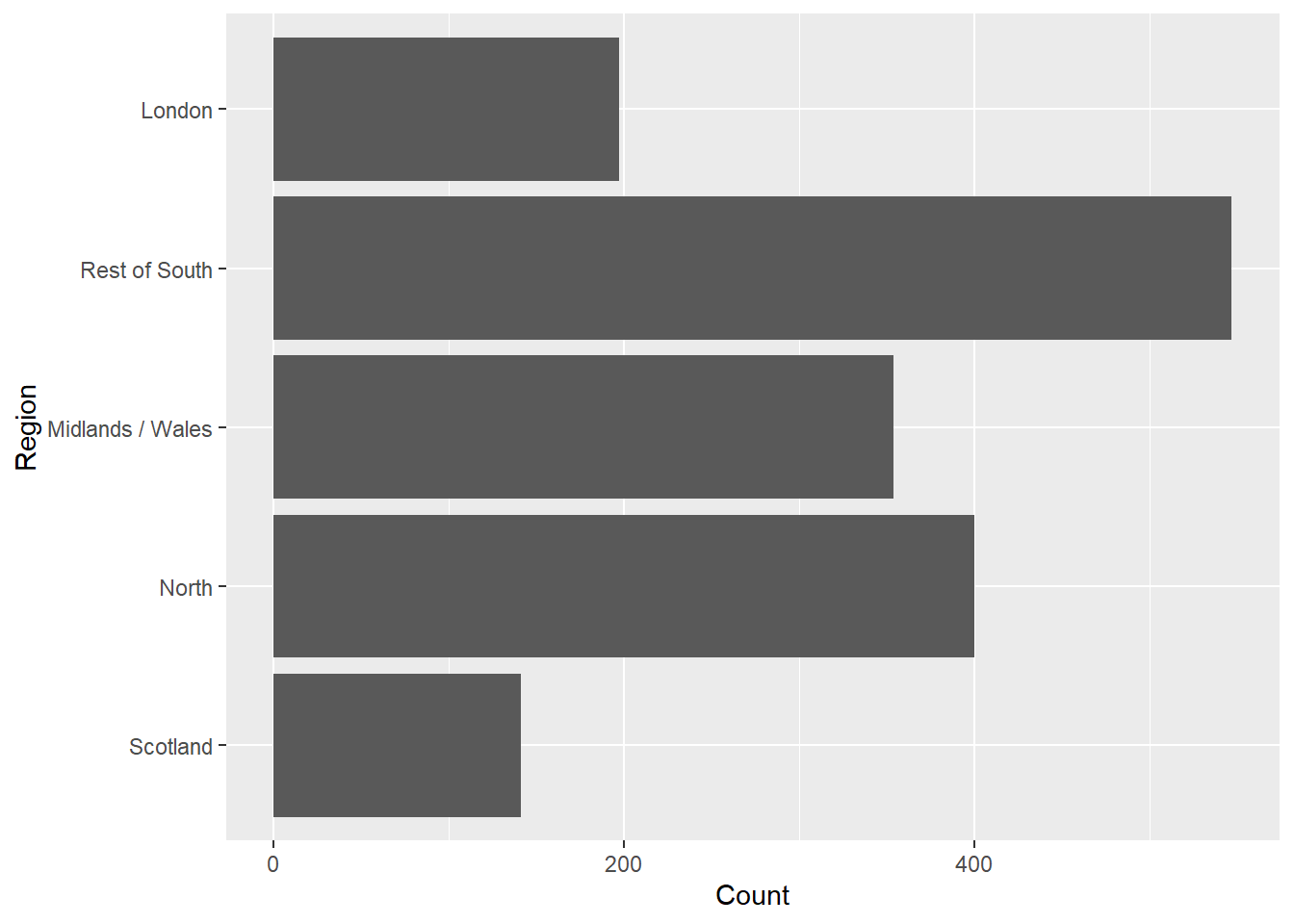
Exercise 3
Nous allons maintenant voir quelle proportion de personnes dans chaque région pense que la Grande-Bretagne a eu raison ou tort de quitter l’UE.
Commencez par créer un graphique en barres empilées qui montre la proportion de chaque réponse dans chaque région.
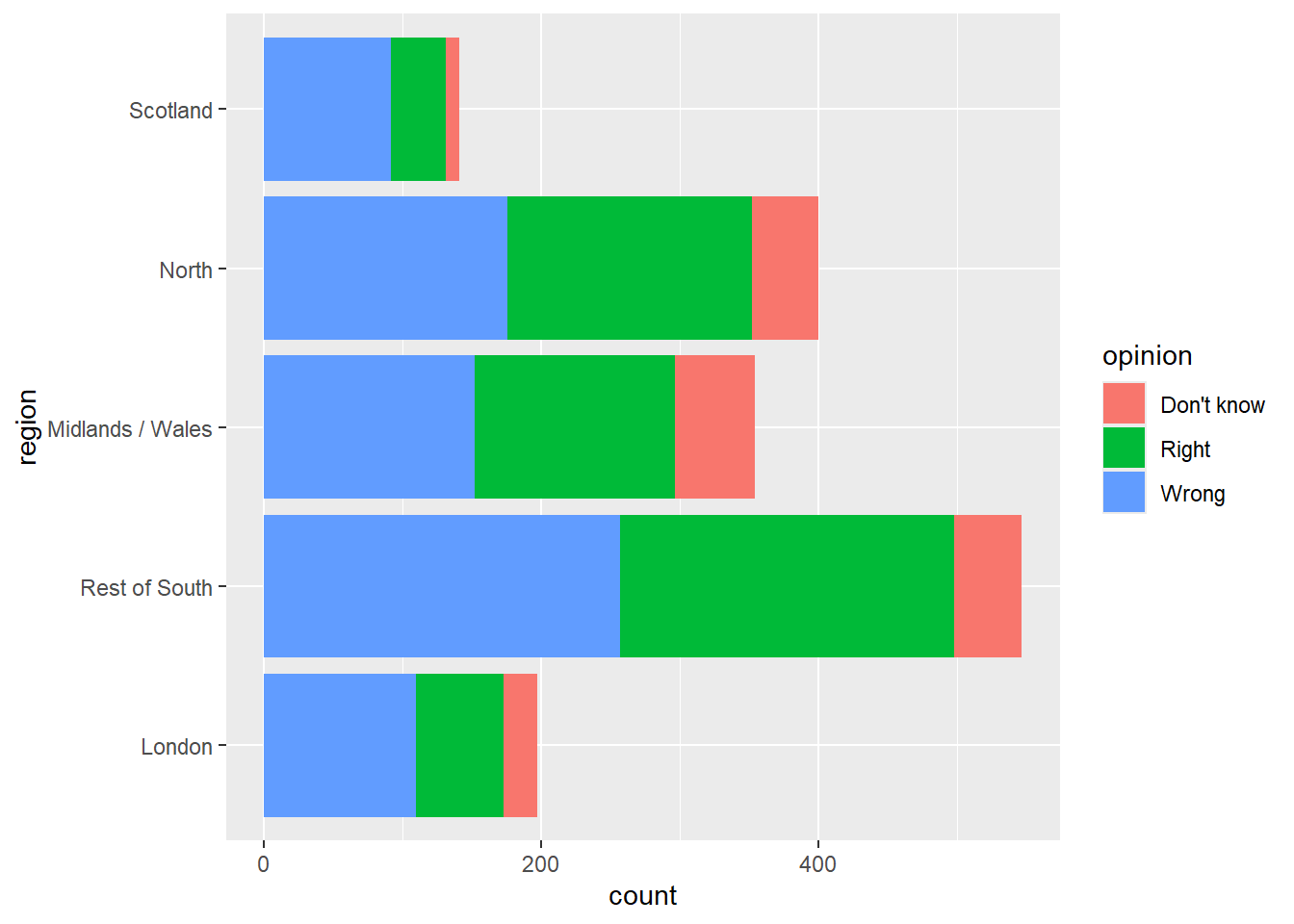
Est-ce lisible ? Quelle serait une alternative ?
Essayez d’utiliser des facettes maintenant :
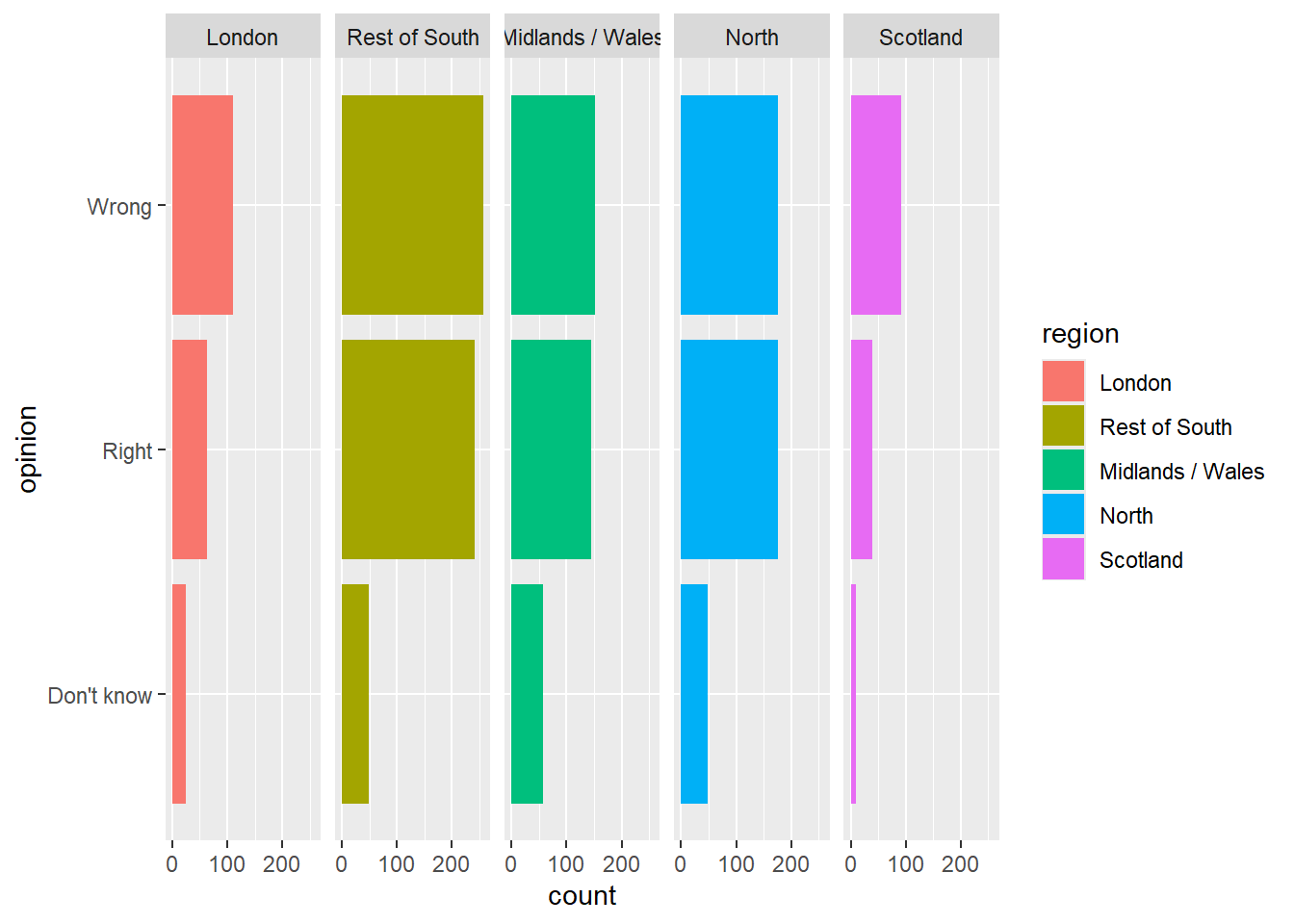
Voyez-vous de la redondance dans le graphe proposé ?
Comment pourrions nous l’éviter ?
Exercice 4
La redondance peut avoir son intérêt.
Reproduisez le graphe suivant.
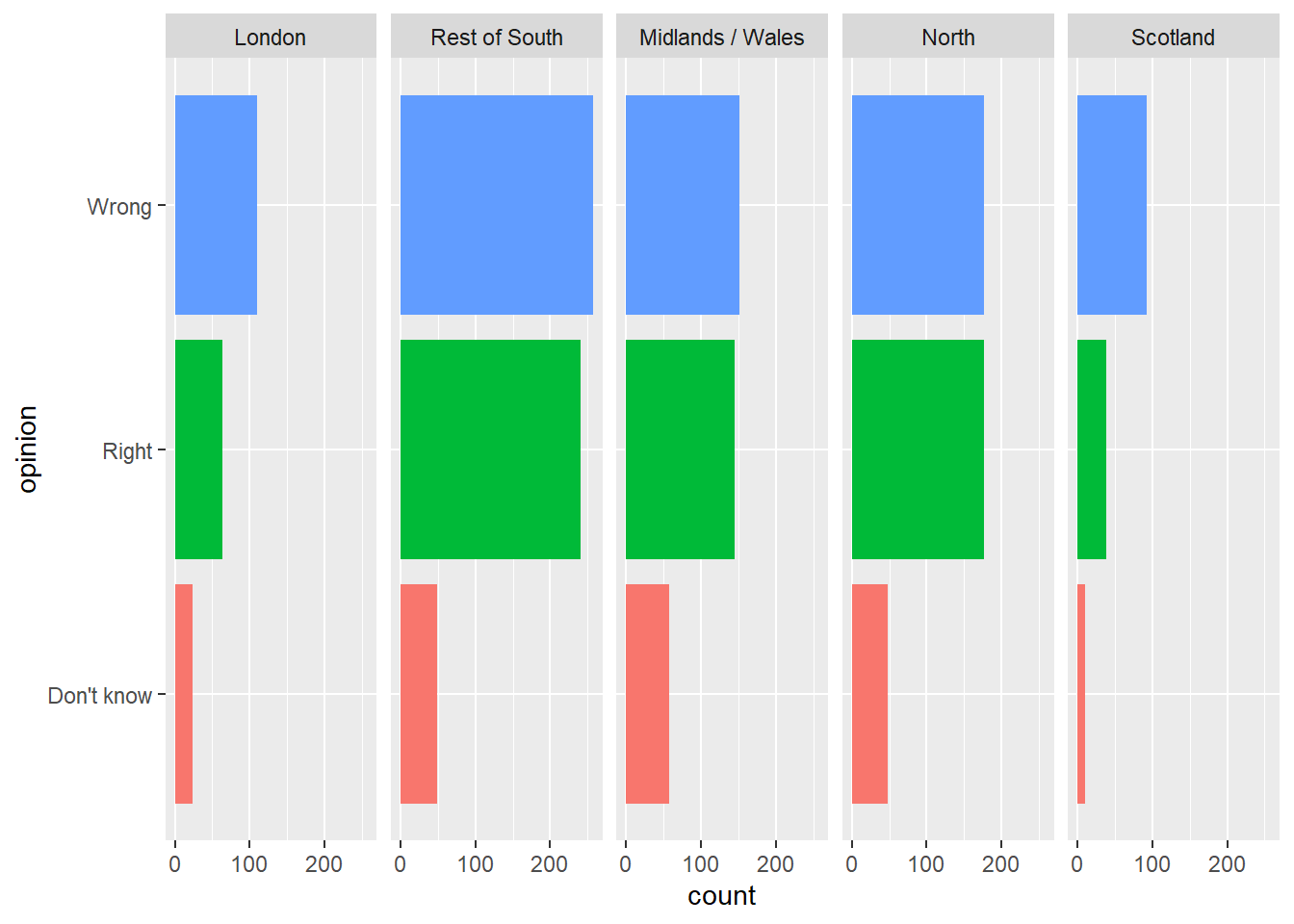
Ici, il y a en effet de la redondance avec la couleur pour les catégories mais il n’y en a pas dans la légende !
Nettoyer les labels et autres de telle sorte à obtenir le graphique suivant:
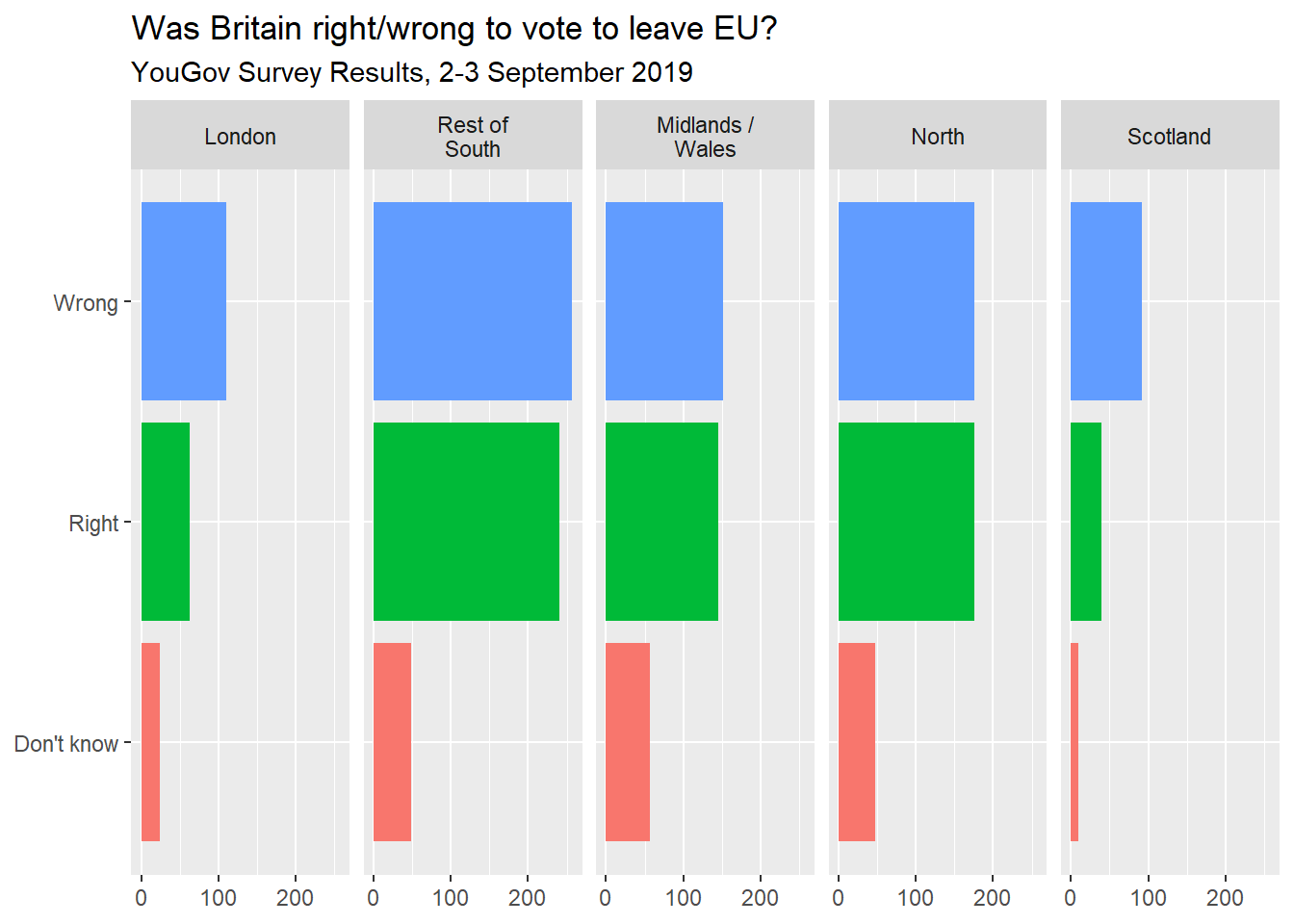
Pour régler l’espacement dans les facettes, utilisez l’option labeller = label_wrap_gen(width = XX) où XX est un nombre définissant la largeur maximale autorisée.
Exercice 5
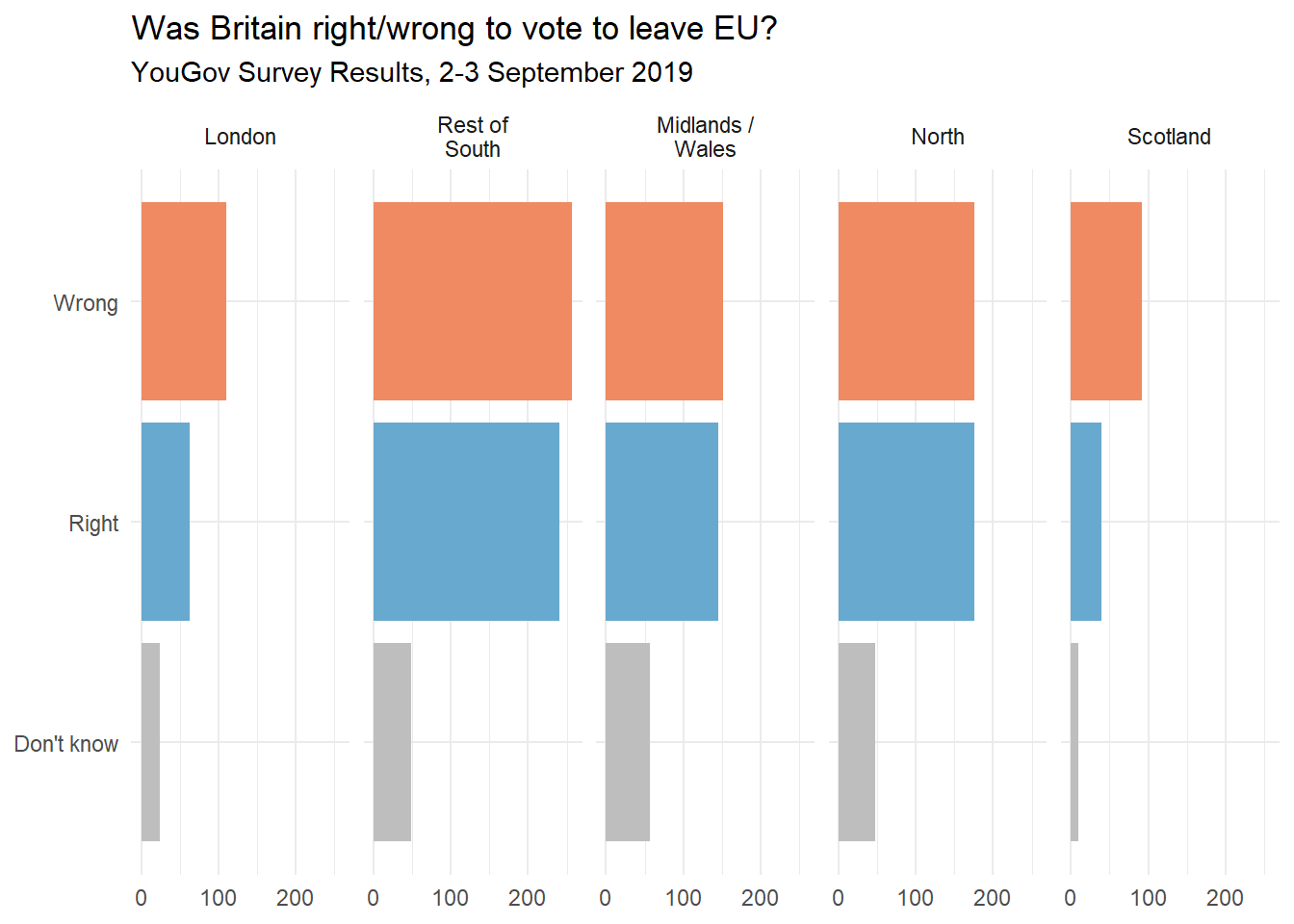
Pour terminer, nous allons régler les couleurs !
Visitez le site https://colorbrewer2.org et choisissez une palette de couleurs adaptée pour représenter les opinions. Réflechissez notamment au type : sequentiel vs divergent vs qualitatif !
Appliquez cette palette à votre graphique.
Pour cela, utilisez la fonction scale_fill_manual(values = c(...)) où vous devez indiquer les couleurs choisies dans le vecteur c(...). Par exemple c("Wrong" = "#000000", ...), où #000000 est le code hexadécimal de la couleur noire.
Vous pouvez également essayer d’ajouter la fonction theme_minimal() pour changer le thème du graphique.
Au final, vous devriez obtenir quelque chose comme ceci:
Les tendances de l’emploi du personnel d’enseignement
L’association américaine des professeurs d’université (AAUP) est une association à but non lucratif composée de professeurs et d’autres professionnels du milieu universitaire. Ce rapport compilé par l’AAUP montre les tendances des employés du personnel d’enseignement entre 1975 et 2011, et contient une image très similaire à celle donnée ci-dessous.
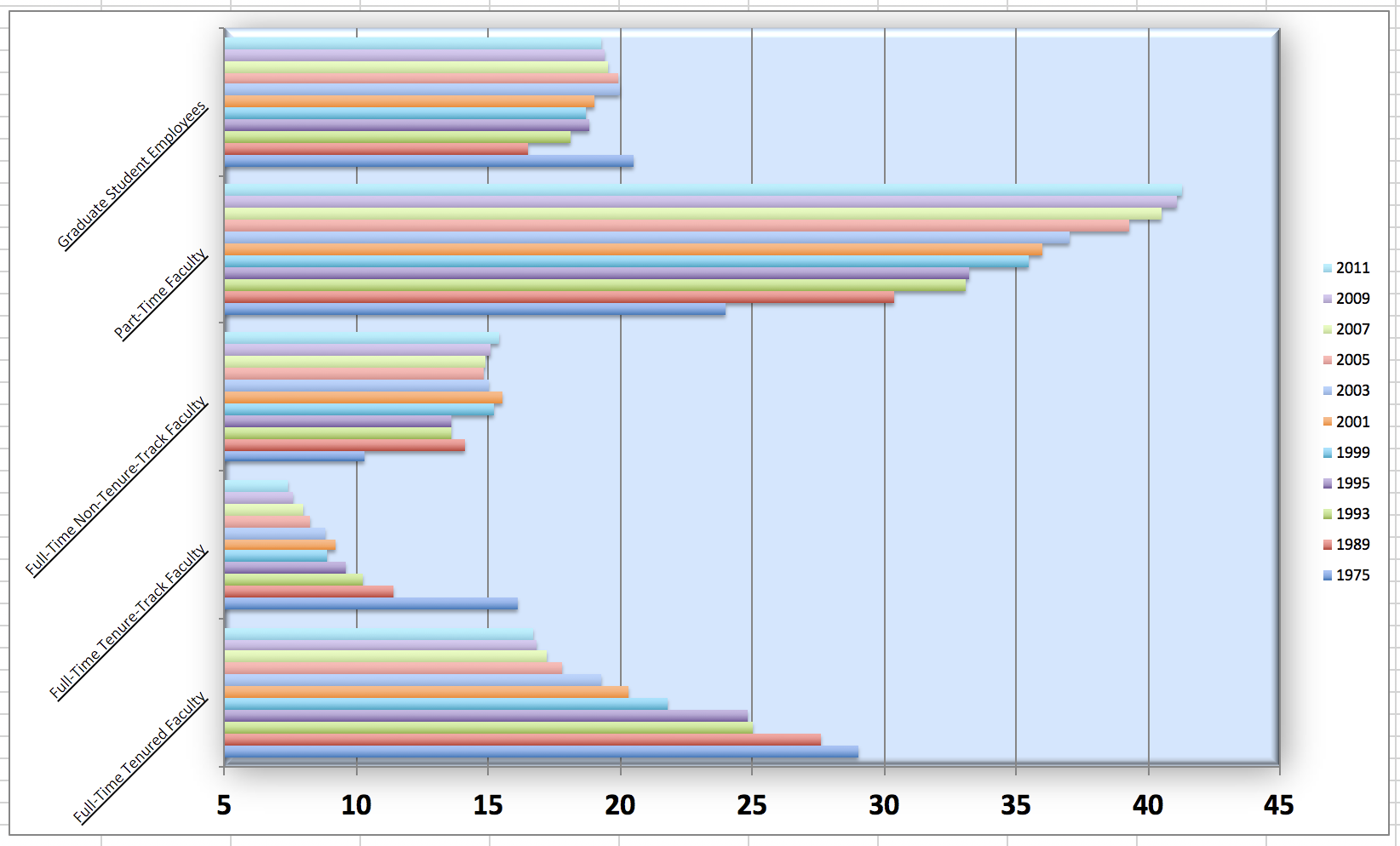
Commençons par charger les données utilisées pour créer ce graphique.
staff <- read_csv("data/instructional-staff.csv")Chaque ligne de cet ensemble de données représente un type de personnel enseignant, et les colonnes sont les années pour lesquelles nous disposons de données. Les valeurs sont le pourcentage d’embauches de ce type de personnel pour chaque année.
# A tibble: 5 × 12
faculty_type `1975` `1989` `1993` `1995` `1999` `2001` `2003` `2005` `2007`
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Full-Time Tenu… 29 27.6 25 24.8 21.8 20.3 19.3 17.8 17.2
2 Full-Time Tenu… 16.1 11.4 10.2 9.6 8.9 9.2 8.8 8.2 8
3 Full-Time Non-… 10.3 14.1 13.6 13.6 15.2 15.5 15 14.8 14.9
4 Part-Time Facu… 24 30.4 33.1 33.2 35.5 36 37 39.3 40.5
5 Graduate Stude… 20.5 16.5 18.1 18.8 18.7 19 20 19.9 19.5
# ℹ 2 more variables: `2009` <dbl>, `2011` <dbl>Exercise 1
Pour reproduire cette visualisation, nous devons d’abord remodeler les données pour avoir une variable pour le type de personnel enseignant et une variable pour l’année. En d’autres termes, nous allons convertir les données du format large au format long.
Avant de faire cela, un exercice de réflexion : Combien de lignes le format long aura-t-il ?
À l’aide de la fonction appropriée, convertissez les données du format large au format long et enregistrez le résultat dans une nouvelle variable appelée staff_long.
Voilà ce que vous devriez avoir :
staff_long# A tibble: 55 × 3
faculty_type year value
<chr> <dbl> <dbl>
1 Full-Time Tenured Faculty 1975 29
2 Full-Time Tenured Faculty 1989 27.6
3 Full-Time Tenured Faculty 1993 25
4 Full-Time Tenured Faculty 1995 24.8
5 Full-Time Tenured Faculty 1999 21.8
6 Full-Time Tenured Faculty 2001 20.3
7 Full-Time Tenured Faculty 2003 19.3
8 Full-Time Tenured Faculty 2005 17.8
9 Full-Time Tenured Faculty 2007 17.2
10 Full-Time Tenured Faculty 2009 16.8
# ℹ 45 more rowsExercise 2
Quelles dimensions souhaite-t-on représenter dans le graphique ? De quelle type sont-elles (quantitative, qualitative, …) ?
Selon vous, quel type de graphique serait le plus approprié pour représenter ces données ?
Exercise 3
Commencez par reproduire un graphe en barres comme celui présent dans le rapport de l’AAUP.
Comment pouvez-vous améliorer ce graphique ? Pensez à des aspects tels que la lisibilité, les couleurs, les étiquettes, le titre, etc.
Exercise 4
Proposez un autre type de graphe plus adapté pour représenter ces données.
Une possibilité est présentée ci-dessous :
staff_long %>%
ggplot(aes(x = year, y = value, color = faculty_type)) +
geom_line()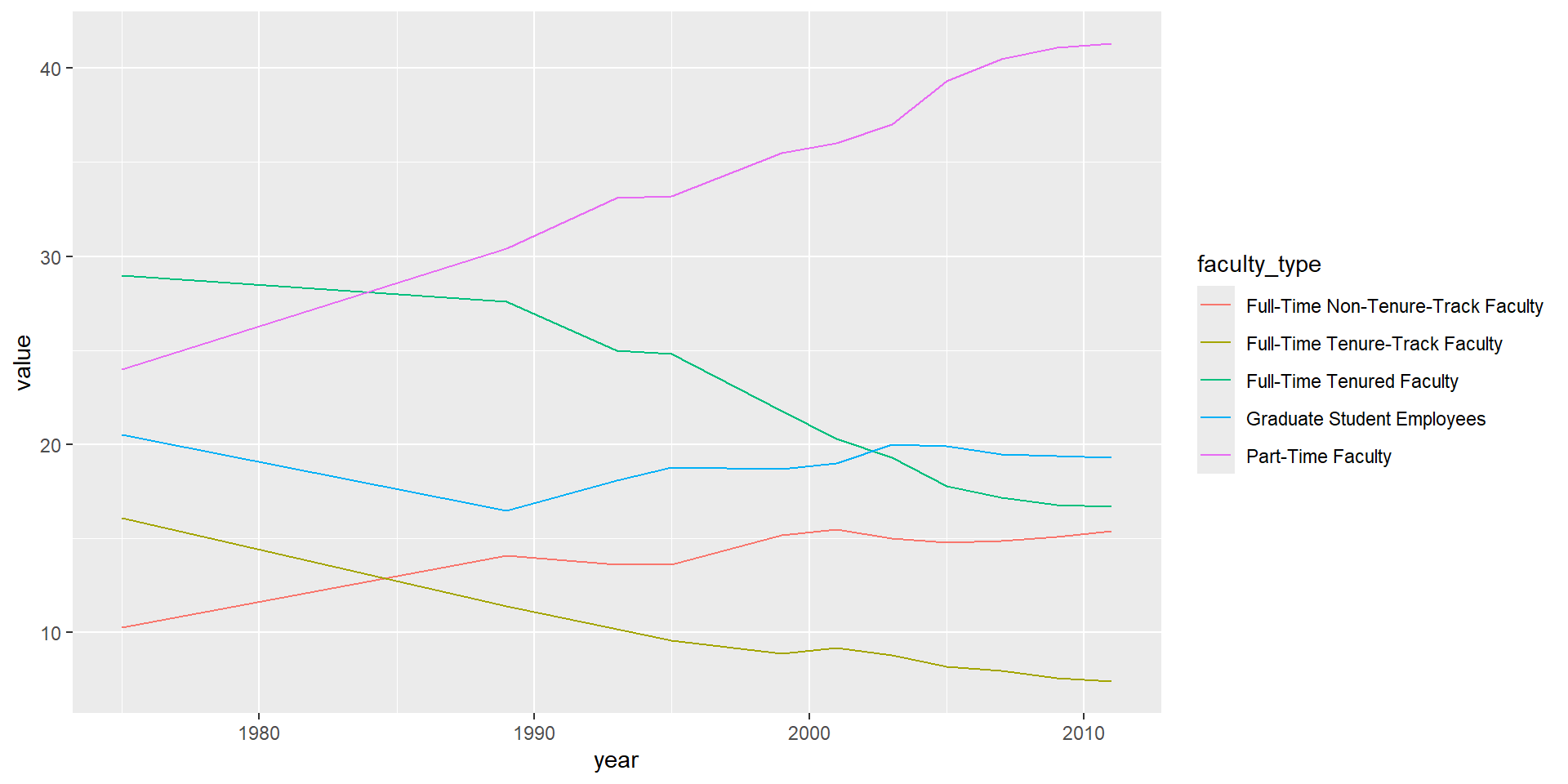
Reproduisez ce graphique ou proposez-en un autre. Proposez des améliorations en prenant en compte le message important de ce graphe.
🧶 ✅ ⬆️ Knit, commit, and push ! N’oubliez pas le message de commit.
Pêcheries
Le département des pêcheries et de l’aquaculture de l’Organisation des Nations Unies pour l’alimentation et l’agriculture collecte des données sur la production halieutique des pays. Cette page Wikipedia répertorie la production halieutique des pays pour 2016. Pour chaque pays, le tonnage de la capture et de l’aquaculture est indiqué. Notez que les pays dont la récolte totale était inférieure à 100 000 tonnes ne sont pas inclus dans la visualisation.
Un chercheur vous a partagé la visualisation suivante qu’il a créée à partir de ces données. 😳
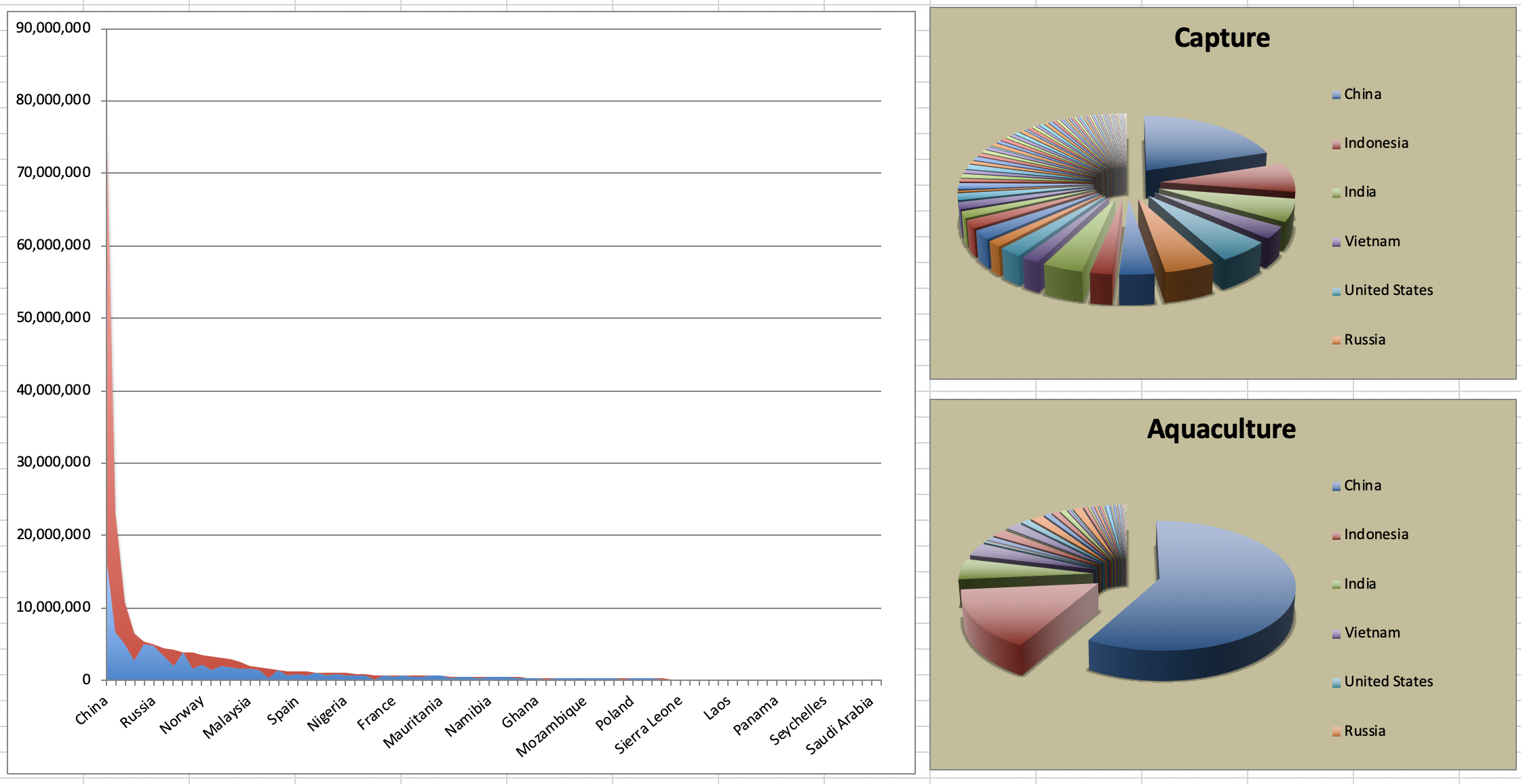
Exercise 5
Pouvez-vous l’aider à améliorer cette visualisation ? Quelles sont les principales lacunes de cette visualisation ?
Exercise 6
Vous pouvez charger les données avec le code suivant :
fisheries <- read_csv("data/fisheries.csv")Essayez de répondre aux problèmes que vous avez identifiés dans l’exercice précédent en créant une nouvelle visualisation des données.
🧶 ✅ ⬆️ Knit, commit, and push ! N’oubliez pas le message de commit.
Plus de mauvais exemples
Vous en voulauez plus ? Voici quelques ressources supplémentaires avec des exemples de mauvaises visualisations :