
Lab 08 - Hotel Bookings
Le but de ce laboratoire est de pratiquer la modélisation de données.
Pour commencer
Nous allons utiliser GitHub Classroom pour que vous puissiez rendre vos réponses. Sur le portail de cours, vous trouverez un lien vers un assignment.
- Cliquez sur le lien
- Connectez vous avec votre compte Github si ce n’est pas fait
- Acceptez l’assignment
- Liez votre compte avec votre nom d’étudiant
Vous devriez maintenant voir un repository appelé Lab08-[votre-username] où devrait être votre nom d’utilisateur GitHub.
Sur la page du repository:
- Cliquez sur le bouton vert:

- Copiez le lien terminant en
.git- Quelque chose ressemblant à
https://github.com/PRO1036/lab08-[votre-username].git
- Quelque chose ressemblant à
Dans RStudio:
- Fichier > Nouveau Projet
- Version Control > Git
- Dans Repository URL : indiquez l’adresse copiée à l’étape précédente
- Choisissez un nom pour le dossier qui sera créé, par exemple “Lab02”
- Choisissez où vous voulez créer le projet dans votre ordinateur.
Cela va copier les fichiers présents sur GitHub, et les copier dans le dossier spécifié. Dans le YAML, le output est réglé sur "github_document". Cela permet d’obtenir un format adapté à GitHub. Notamment, votre fichier final sera un fichier Markdown (.md).
Packages
Nous utiliserons le package tidyverse pour la manipulation des données et le package tidymodels pour la modélisation. Vous pouvez le charger en exécutant ce qui suit dans votre Console :
library(tidyverse)
library(tidymodels)
library(lubridate)Données
Dans ce laboratoire, nous allons utiliser un ensemble de données sur les réservations d’hôtels, issue de l’article de (Antonio et al., 2019). L’objectif est de prédire le type d’hôtel et si une réservation inclut des enfants ou non. Les données contiennent des informations sur les réservations, telles que le type d’hôtel, la durée du séjour, le nombre de personnes, etc.Vous pouvez en apprendre plus ici
Le jeu de données étant un peu volumineux, nous allons le charger directement depuis Internet.
Exercices
Importation des données
Commencez par importer les données dans une variable hotels.
hotels <- read_csv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-02-11/hotels.csv")Analyse Exploratoire
Exercice 1
1.1 Combien le jeu de données contient-il d’observation et de variables ?
1.2 Quels sont les types d’hôtels présents dans le jeu de données ? Combien y a-t-il de réservations pour chaque type d’hôtel ?
1.3 Créez une nouvelle colonne Kids qui vaudra "Yes" si la réservation compte au moins un enfant ou un bébé. Transformez-la en facteur.
1.4 Quel est le pourcentage de réservations avec des enfants ?
1.5 Nous allons terminer par quelques transformations de données. Créez un nouveau tableau hotels_clean qui :
- Conservez uniquement les réservations non annulées.
- Créez une nouvelle colonne
total_stayqui correspond au nombre total de nuits passées à l’hôtel (somme des nuits en semaine et des nuits en week-end). - Créez une nouvelle colonne
parkingqui vaut “Yes” si le nombre de places de parking réservées est supérieur à 0, et “No” sinon. Transformez la en facteur. - Créez une nouvelle colonne
arrival_datequi est composées des colonnesarrival_date_year,arrival_date_monthetarrival_date_day_of_month. Vous pouvez utiliser les fonctionespastepour regrouper les trois colonnes dans une chaine de texte, puisymd()du packagelubridate. - Retirez les colonnes inutiles
is_canceled,reservation_status,children,babies,country,arrival_date_year,arrival_date_month,arrival_date_day_of_month,arrival_date_week_number,reservation_status_date,agentetcompany. - Transformez les colonnes de type caractère en facteurs.
Vous devriez obtenir un tableau de 75166 observation et 26 variables.
Modélisation
Exercice 2 - Séparation des données
Cette section consiste à préparer les données pour la modélisation. Il y aura une partie aléatoire, donc pour que vos résultats soient reproductibles, nous allons fixer la graine aléatoire avec set.seed(1036).
set.seed(1036) # pour la reproductibilité2.1 Pour éviter de rallonger les temps de traitement, nous allons travailler avec un sous-ensemble des données. Créez un sous-ensemble hotels_small qui contient 10 000 observations aléatoires du jeu de données initial. Utilisez la fonction sample_n.
2.2 Séparez vos données en un ensemble d’entraînement et un ensemble de test en utilisant 80% pour l’entrainement. Utilisez le paramètre strata pour indiquez que vous souhaitez conserver la même proportion de la variable Kids dans les deux jeux.
2.3 Calculez la proportion de réservations avec des enfants dans chaque ensemble de données. Les proportions doivent être similaires. Elles peuvent varier de celle obtenu dans l’exercice 1.
Exercice 3 - Entrainement et évaluation du modèle
3.1 Fittez un modèle de régression logistique appelé hotel_fit sur l’ensemble d’entrainement. Utilisez la variable hotel comme variable à prédire, et toutes les autres variables comme prédicteurs.
3.2 Utilisez le modèle pour faire des prédictions sur l’ensemble de test. Créez hotel_pred_class et hotel_pred_prob pour avoir deux tableaux, l’un avec la classe prédite et l’autre avec la probabilité associée. Observez la différence entre les deux tableaux (colonnes différentes).
3.3 Calculez la matrice de confusion pour évaluer la performance du modèle sur l’ensemble de test. Utilisez la fonction conf_mat()
Truth
Prediction City Hotel Resort Hotel
City Hotel 1121 213
Resort Hotel 99 5683.4 Identifiez les faux positifs et les faux négatifs à partir de la matrice de confusion. Quel est le taux de faux positifs et de faux négatifs ? Calculez la sensibilité et la spécificité. Commentez ces valeurs.
3.5 Affichez une courbe ROC pour évaluer la performance du modèle. Commentez la courbe obtenue.
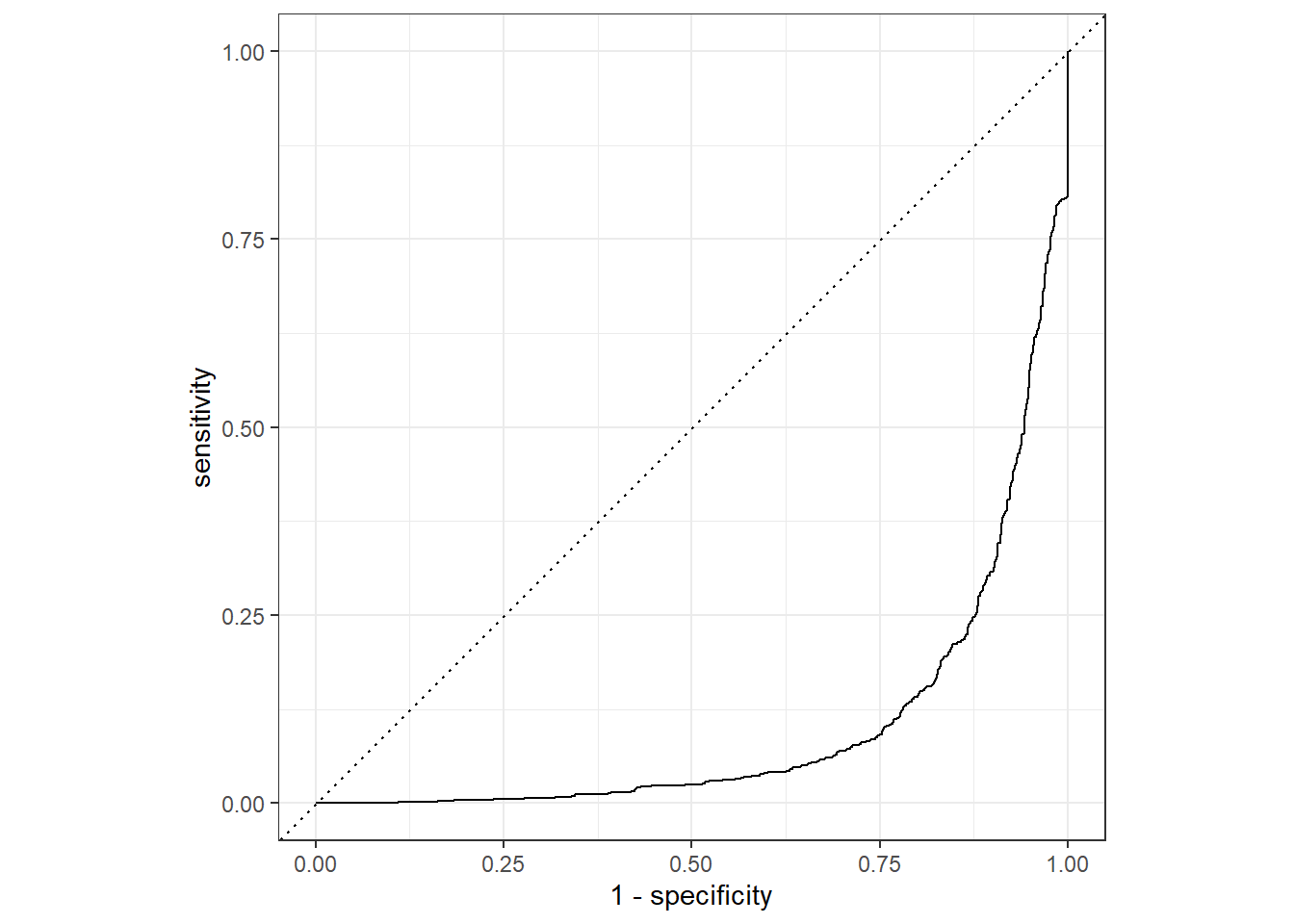
3.6 En jouant sur les variables utilisées pour faire la prédiction, essayez d’améliorer la performance du modèle. Par exemple, vous pouvez essayer de supprimer certaines variables.
Exercice 4 - Prédiction de la présence d’enfants
4.1 Pour terminer, reproduisez les étapes précédentes, 2.1 à 3.6 pour prédire si une réservation inclut des enfants ou non (variable Kids).
- Séparez les données en un ensemble d’entrainement et un ensemble de test.
- Fittez un modèle de régression logistique.
- Évaluez la performance du modèle avec une matrice de confusion et une courbe ROC.
References
Antonio, N., de Almeida, A. and Nunes, L. (2019). Hotel booking demand datasets. Data in Brief, 22, 41–49. https://doi.org/10.1016/j.dib.2018.11.126