library(tidyverse)
library(tidymodels)
library(lubridate)Lab 09 - The Office

Le but de ce laboratoire est de pratiquer la modélisation de donnée, le feature engineering et le rééchantillonage.
Pour commencer
Nous allons utiliser GitHub Classroom pour que vous puissiez rendre vos réponses. Sur le portail de cours, vous trouverez un lien vers un assignment.
- Cliquez sur le lien
- Connectez vous avec votre compte Github si ce n’est pas fait
- Acceptez l’assignment
- Liez votre compte avec votre nom d’étudiant
Vous devriez maintenant voir un repository appelé Lab09-[votre-username] où devrait être votre nom d’utilisateur GitHub.
Sur la page du repository:
- Cliquez sur le bouton vert:

- Copiez le lien terminant en
.git- Quelque chose ressemblant à
https://github.com/PRO1036/lab09-[votre-username].git
- Quelque chose ressemblant à
Dans RStudio:
- Fichier > Nouveau Projet
- Version Control > Git
- Dans Repository URL : indiquez l’adresse copiée à l’étape précédente
- Choisissez un nom pour le dossier qui sera créé, par exemple “Lab02”
- Choisissez où vous voulez créer le projet dans votre ordinateur.
Cela va copier les fichiers présents sur GitHub, et les copier dans le dossier spécifié. Dans le YAML, le output est réglé sur "github_document". Cela permet d’obtenir un format adapté à GitHub. Notamment, votre fichier final sera un fichier Markdown (.md).
Packages
Nous utiliserons le package tidyverse pour la manipulation des données et le package tidymodels pour la modélisation. Vous pouvez le charger en exécutant ce qui suit dans votre Console :
Données
Dans ce laboratoire, nous allons essayer de prédire le score obtenu par les épisodes de The Office. Pour cela, nous allons utiliser un jeu de données fourni par Brad Lindblad.
Les données sont distribuées sous forme de package R. Le package peut être installé avec la commande :
install.packages("schrute")Il est ensuite possible de charger le jeu de données avec la commande :
library(schrute)Exercices
Importation des données
Si vous avez correctement charger le package, vous devriez pouvoir voir les données directement:
glimpse(theoffice)Rows: 55,130
Columns: 12
$ index <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16…
$ season <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ episode <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ episode_name <chr> "Pilot", "Pilot", "Pilot", "Pilot", "Pilot", "Pilot",…
$ director <chr> "Ken Kwapis", "Ken Kwapis", "Ken Kwapis", "Ken Kwapis…
$ writer <chr> "Ricky Gervais;Stephen Merchant;Greg Daniels", "Ricky…
$ character <chr> "Michael", "Jim", "Michael", "Jim", "Michael", "Micha…
$ text <chr> "All right Jim. Your quarterlies look very good. How …
$ text_w_direction <chr> "All right Jim. Your quarterlies look very good. How …
$ imdb_rating <dbl> 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6, 7.6…
$ total_votes <int> 3706, 3706, 3706, 3706, 3706, 3706, 3706, 3706, 3706,…
$ air_date <chr> "2005-03-24", "2005-03-24", "2005-03-24", "2005-03-24…theoffice %>% head()# A tibble: 6 × 12
index season episode episode_name director writer character text
<int> <int> <int> <chr> <chr> <chr> <chr> <chr>
1 1 1 1 Pilot Ken Kwapis Ricky Gervais;St… Michael All …
2 2 1 1 Pilot Ken Kwapis Ricky Gervais;St… Jim Oh, …
3 3 1 1 Pilot Ken Kwapis Ricky Gervais;St… Michael So y…
4 4 1 1 Pilot Ken Kwapis Ricky Gervais;St… Jim Actu…
5 5 1 1 Pilot Ken Kwapis Ricky Gervais;St… Michael All …
6 6 1 1 Pilot Ken Kwapis Ricky Gervais;St… Michael Yes,…
# ℹ 4 more variables: text_w_direction <chr>, imdb_rating <dbl>,
# total_votes <int>, air_date <chr>Analyse Exploratoire
Exercice 1
1.1 Créez un tableau episodes indiquant pour chaque épisode, le titre de l’épisode, sa saison, le numéro de l’épisode, la date de sa diffusion, son score IMDB et le nombre de votes. Assurez-vous que les épisodes soient dans l’ordre.
Vous devriez obtenir un tableau de 186 observations et 6 variables.
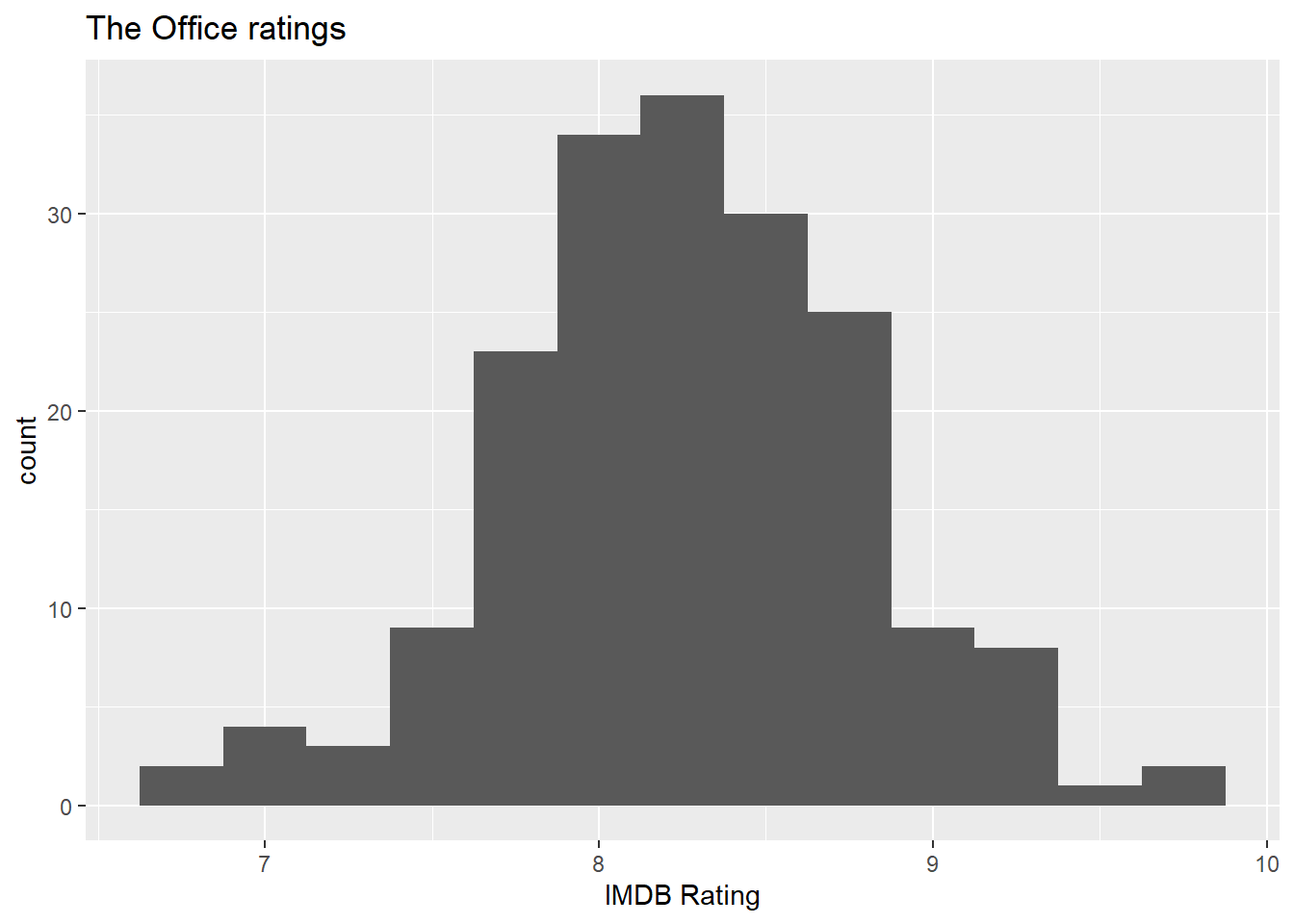
1.2 Produisez un histogramme des scores IMDB des épisodes.
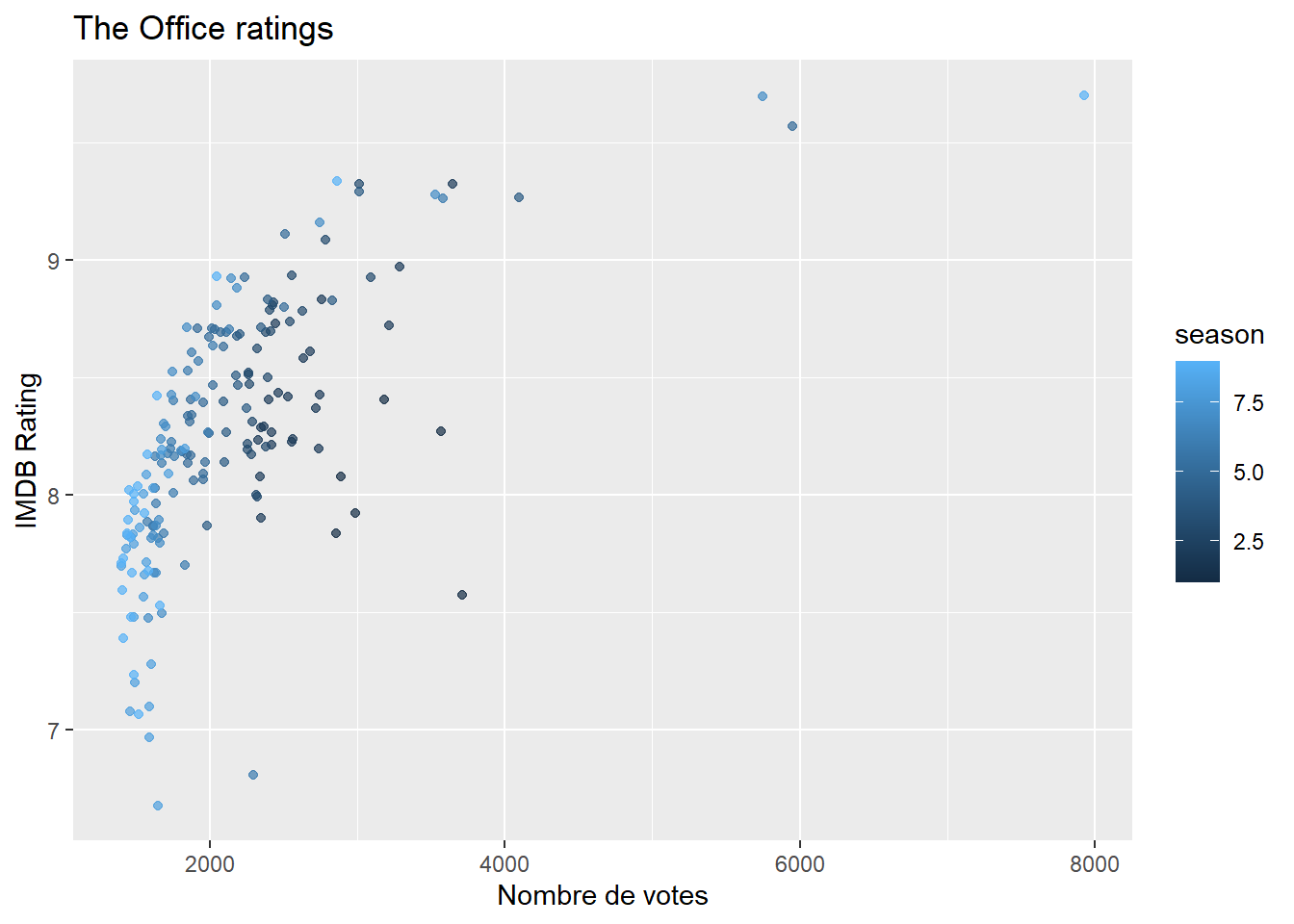
1.3 Créez un nuage de points représentant le score IMDB en fonction du nombre de votes. Colorez les points en fonction de la saison.
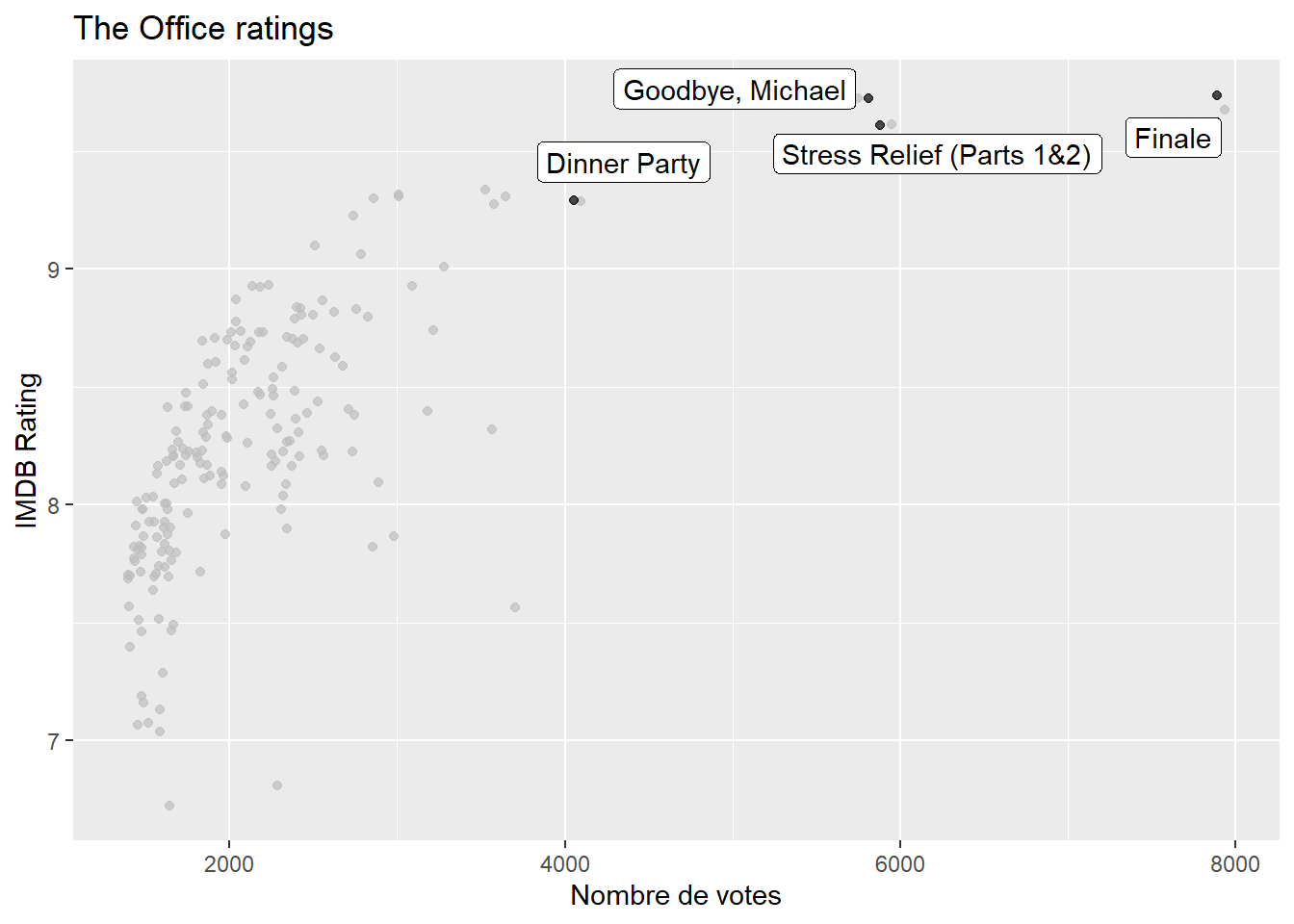
1.4 En filtrant votre tableau, identifiez les quatres épisodes qui semblent être des outliers en terme de nombres de votes.
(Optionnel) Reproduisez le nuage de points précédent en mettant en évidence ces épisodes à l’aide du package gghighlight.
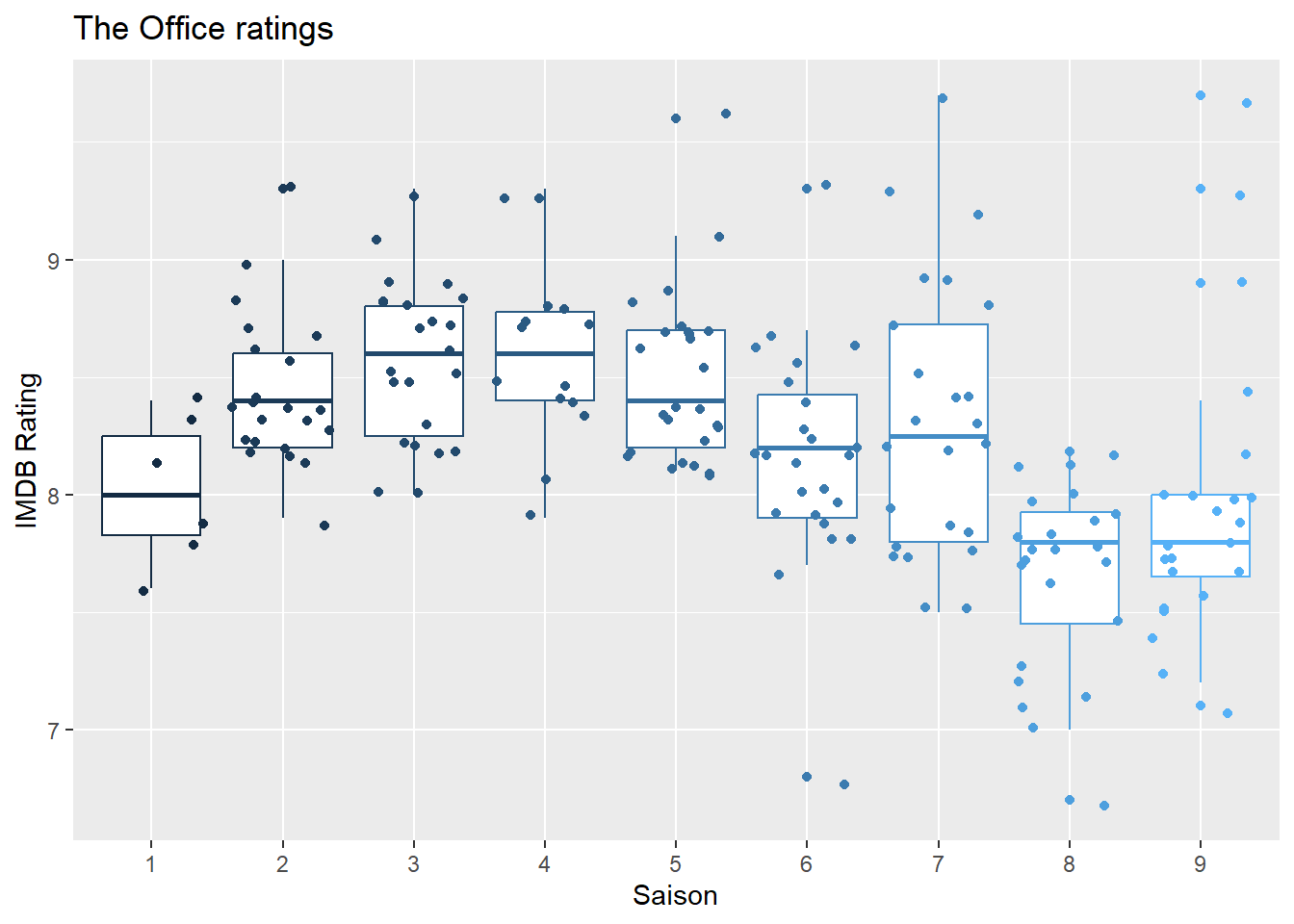
1.5 Produisez un boxplot pour chaque saison montrant la distribution des scores IMDB.
Feature Engineering
Exercice 2
2.1 Calculez la pourcentage de répliques prononcées par Jim, Pam, Michael et Dwight pour chaque épisode de The Office. Créez un tableau office_lines contenant le titre de l’épisode, la saison, le numéro de l’épisode, et les pourcentages de répliques prononcées par chacun des quatre personnages.
Vous devriez obtenir un tableau de 186 observations et 7 variables.
2.2 Créez trois nouvelles colonnes halloween, valentines, et christmas qui vaudront 1 si l’épisode est lié à la fête correspondante, et 0 sinon. Pour cela:
- Commencez par mettre tous le texte en minuscule avec la fonction
tolower(). - Utilisez la fonction
str_detect()du packagestringrpour détecter si le titre de l’épisode contient des mots clés liés à la fête.- Pour Halloween, cherchez le mot clé
"halloween". - Pour la Saint-Valentin, cherchez le mot clé
"valentine". - Pour Noël, cherchez les mots clés
"christmas"ou"holiday".
- Pour Halloween, cherchez le mot clé
Vous pouvez faire cela en une opération ou en plusieurs étapes, en créant trois tableaux, un pour chaque fête, puis en les regroupant (avec une jointure).
Votre tableau final s’appelera office_special
Vous devriez obtenir un tableau de 186 observations et 13 variables.
2.3 Ajoutez une colonne michael qui vaut 1 si Michael Scott (Steve Carrell) est présent dans l’épisode, et 0 sinon.
Il faut savoir que le personnage de Michael Scott est présent dans les saisons 1 à 7.
Cela nous permettra d’avoir un tableau de données final, appelé office_df.
Vous devriez obtenir un tableau de 186 observations et 14 variables.
Nous avons un jeu de données qui pourra être utilisé pour la modélisation.
Modélisation
Exercice 3 - Séparation des données
3.1 Séparez les données en un ensemble d’entraînement (75%) et un ensemble de test (25%). Utilisez la seed set.seed(1036) pour que vos résultats soient reproductibles.
Ecercice 4 - Modèle 1
4.1 Préparez un modèle de régression linéaire appelé office_mod_1.
4.2 Créez une recette office_rec_1 qui utilise comme prédicteurs season, episode, total_votes et air_date pour prédire imdb_rating. La recette doit convertir air_date en date, extraire le mois de la date de diffusion, supprimer la variable air_date, créer des variables dummy pour le mois, et supprimer les prédicteurs à variance nulle.
4.3 Créez un workflow office_wflow_1 qui combine la recette et le modèle.
4.4 Fittez le workflow sur l’ensemble d’entraînement pour créer office_fit_1.
4.5 Évaluez la performance du modèle sur l’ensemble de d’entrainement en calculant le RMSE et le R². Pour cela, tutilisez les fonctions rmse() et rsq() avec les prédictions obtenues.
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.352# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rsq standard 0.566Vous devriez obtenir un RMSE d’environ 0.35 et un R² d’environ 0.57.
4.6 Faites une validation croisée à 5 plis sur l’ensemble d’entraînement pour évaluer la performance du modèle. Utilisez la fonction vfold_cv() pour créer les plis, puis utilisez la fonction fit_resamples() pour fitter le modèle sur chaque pli. Enfin, utilisez la fonction collect_metrics() pour obtenir les métriques de performance (RMSE et R²).
# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 0.392 5 0.0448 pre0_mod0_post0
2 rsq standard 0.516 5 0.0786 pre0_mod0_post0Exercice 5 - Modèle 2
5.1 Préparez un modèle de régression linéaire appelé office_mod_2
5.2 Créez zune recette office_rec_2 qui met à jour le rôle de episode_name pour ne pas être un prédicteur, qui enlève air_date comme prédicteur, et qui enlève tous les prédicteurs à variance nulle.
5.3 Créez un workflow office_wf_2 qui combine la recette et le modèle
5.4 Fittez le workflow sur l’ensemble d’entraînement pour créer office_fit_2.
5.5 Évaluez la performance du modèle sur l’ensemble de d’entrainement en calculant le RMSE et le R². Pour cela, tutilisez les fonctions rmse() et rsq() avec les prédictions obtenues.
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.350# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rsq standard 0.572Vous devriez obtenir un RMSE d’environ 0.36 et un R² d’environ 0.57.
5.6 Faites une validation croisée à 5 plis sur l’ensemble d’entraînement pour évaluer la performance du modèle. Utilisez la fonction vfold_cv() pour créer les plis, puis utilisez la fonction fit_resamples() pour fitter le modèle sur chaque pli. Enfin, utilisez la fonction collect_metrics() pour obtenir les métriques de performance (RMSE et R²).
# 5-fold cross-validation
# A tibble: 5 × 2
splits id
<list> <chr>
1 <split [111/28]> Fold1
2 <split [111/28]> Fold2
3 <split [111/28]> Fold3
4 <split [111/28]> Fold4
5 <split [112/27]> Fold5# A tibble: 2 × 6
.metric .estimator mean n std_err .config
<chr> <chr> <dbl> <int> <dbl> <chr>
1 rmse standard 0.389 5 0.0397 pre0_mod0_post0
2 rsq standard 0.468 5 0.0834 pre0_mod0_post0Exercice 6 - Évaluation finale et Comparaison des modèles
6.1 Évaluez la performance des deux modèles sur l’ensemble de test en calculant le RMSE et le R². Pour cela, tutilisez les fonctions rmse() et rsq() avec les prédictions obtenues.
Modèle 1:
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.351# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rsq standard 0.572Modèle 2:
# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.359# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rsq standard 0.560